
By: Tomi Häkkinen
Cholera to Cancer, it’s all about the data
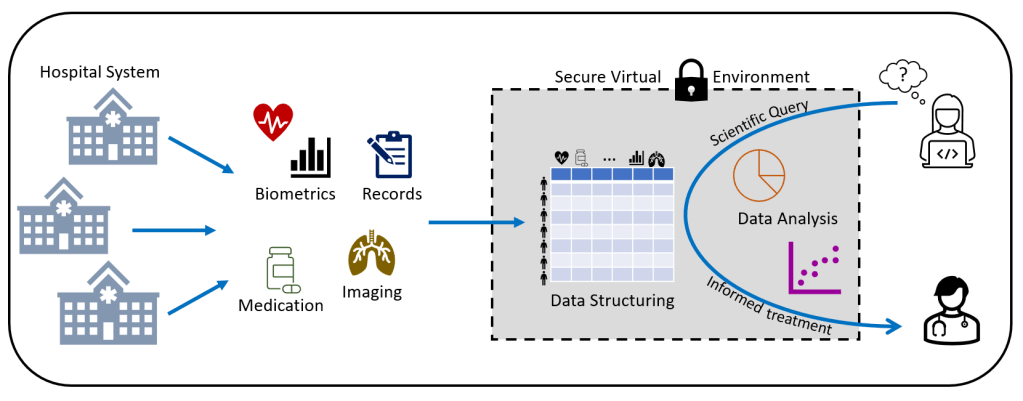
Since the days of London cholera epidemics in 1854, it has been realized that the key to healthcare is ultimately knowledge. Slowly hospitals and universities have been collecting more and more medical data. Now, we’re living in a vast, wild jungle of medical data. Different hospital departments and medical fields have their own ways of collecting data and often measurements are not intended to be shared outside of the department. Data is siloed and fragmented. Without a full picture of the situation, it is next to impossible to figure out more effective care and bring the overall healthcare costs down. Fortunately, the problem of data fragmentation has been recognized and measures have been taken. Hospitals and hospital districts are building data lakes – large, common storages of data that can be accessed easily not only by researchers but also other medical professionals across departmental or other borders. Because data that has been collected during normal health care is very complex and multimodal, ordinary databases are ill-suited for the task. Stored data is also not normalized or otherwise cleaned before researchers gains access. For data privacy, the data itself is often stored in specialized cloud storage with very high security requirements. This means that it is not possible to access the internet from data storage or analysis machines.

Our project
Our immediate goal is to demonstrate the effectiveness of the Tampere University Hospital Data Lake as an analysis environment by exploring a few initial cases. It is known that the type and order of drug treatments have an effect in specially designed clinical studies, but it is not always clear what the better treatment options are.

To make the problem slightly more manageable we focus on prostate cancer at this stage. No cancer is quite like another – sometimes cancer grows slowly and sometimes cancer grows very aggressively. In many cases we do not know which type of cancer a patient may have, so to be on the safe side cancers tend to be treated in quite an invasive manner. Because treatments are so severe, this can lead to immense and unnecessary suffering for the patient. So in our second test case, we’re diving into the data lake to see if there are ways to identify those patients who may have indolent cancer (cancer that would not become symptomatic in a patients lifetime and would not contribute to death) for which harsh treatment can be avoided.
Laws, regulations and technical hurdles
Access to the patient data is heavily regulated by the Act on Secondary Use of Health and Social data. Data access permissions aside (which is no small matter!) technical hurdles are also significant. In short, the hospital district builds a secure analysis environment in some commercial cloud provider systems. Current analysis environments are in their infancy and are primarily built for researchers doing relatively simple analysis with limited datasets in basic software (e.g. Excel). Remember, there is no internet access from the analysis environment, that means no free software installations; no Github, no Docker containers and no common CI/CD practices. This makes life for big data analysts very difficult indeed. Fortunately, the situation is only temporary and there is a lot of system development happening behind the scenes.
How to proceed?
Ultimately hospital data analysis is no different than any other data for analysts. The field is “blessed” with a plethora of methods, each with pros and cons. For example, Principal Component Analysis- may reveal which patients separate from others. Random Forest analysis- may show what measurements are relevant for such separation. But, to get to that point much has to happen beforehand. Almost all data analysis projects start by data wrangling – cleaning up the data and making it usable.
For example, in prostate cancer care, measurements of prostate specific antigen (PSA) are regularly taken. However, sometimes the numerical value is stated as text such as “under 0.5” – something that is perfectly reasonable and valid for clinicians but can really throw data analysts off. And that value may not be very useful as is; PSA is roughly dependent on prostate size. Size can be found from Magnetic Resonance Imaging reports. To get a grasp of that, analysts need skills in Natural Language Processing. Then, usable PSA measurement and prostate size data also need to be linked into other datasets. Pathology images from needle biopsies are one of such crucial datasets. The pathology image data from hospitals can easily reach petabyte scale. It’s no small feat to train Artificial Intelligence to work with such huge datasets!
Hope for the future
All in all hospital data lakes are a crucial development in healthcare. We need data systems and the skills to analyze them in order to treat patients effectively. Also resources are limited – with more knowledge we’re able to stretch our resources to treat many more patients with very high standards. It is a privilege to be part of this process.

Want to learn more about the Finnish Center of Excellence in Tumor Genetics?
Find the latest tweets, videos and blog posts for a peek into the everyday life in cancer research
by following us on Instagram (@tumorgenetics) and Twitter (@CoEinTG)
You can also subscribe to our YouTube channel!
